How to Create Kafka Clusters
Validated on 8 Dec 2022 • Last edited on 2 Oct 2025
Kafka is an open-source distributed event and stream-processing platform built to process demanding real-time data feeds. It is inherently scalable, with high throughput and availability.
Create a Database Cluster Using the CLI
To create a database using doctl, you need to provide values for the --engine, --region, and --size flags. Use the doctl databases options engines, doctl databases options regions, and doctl databases options slugs commands, respectively, to get a list of available values.
Create a Database Cluster Using the API
To create a database using the API, you need to provide values for the engine, region, and size fields, which specify the database’s engine, its datacenter, and its configuration (number of CPUs, amount of RAM, and hard disk space). Use the /v2/databases/options endpoint to get a list of available values.
Create a Database Cluster using the Control Panel
You can create a Kafka database cluster at any time from the Create menu by selecting Databases. This takes you to the Create a Database page.
Choose a datacenter
In the Choose a datacenter section, select the datacenter for your database cluster.

This page lists the datacenters in which you currently have the most resources. The number of resources you have in each datacenter is listed to the right as X resources. Hover over this text to see the specific resources you have in that datacenter.
For the best performance, create your database in the same datacenter as your other DigitalOcean resources.
Choose a database engine
In the Choose a database engine section, choose Kafka.
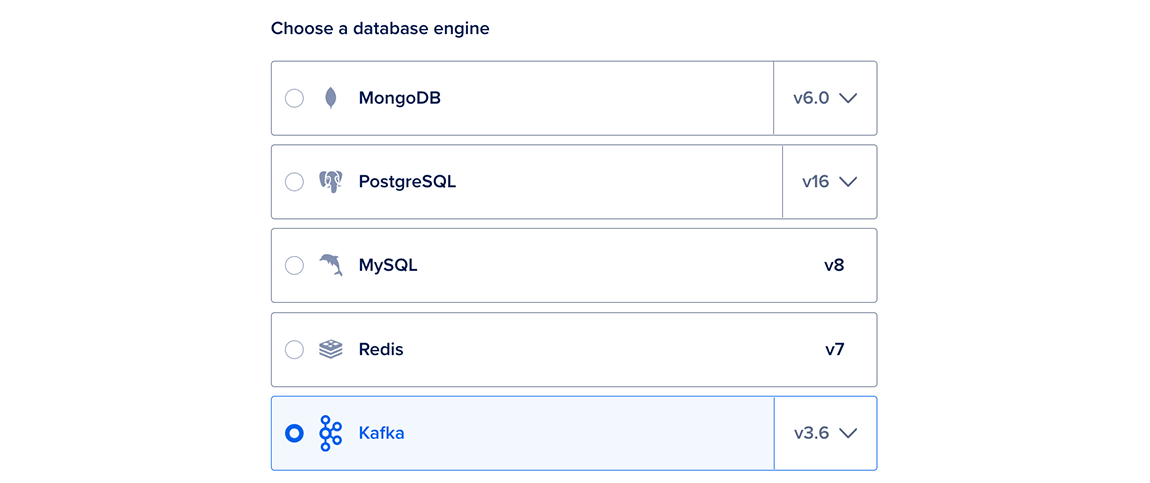
We currently support Kafka v3.6 and v3.7. You cannot change the Kafka version after creating a cluster.
Choose a cluster configuration
In the Choose a cluster configuration section, select a Droplet plan and quantity of nodes for the cluster.
If you select the Shared CPU plan, you also need to select a CPU option. If you select a Dedicated CPU plan, you can customize the number of nodes in the cluster to 3, 6, 9, or 15 nodes. Each option lists its combined monthly cost, equivalent hourly cost, and node specifications. For more options, click See all plans.
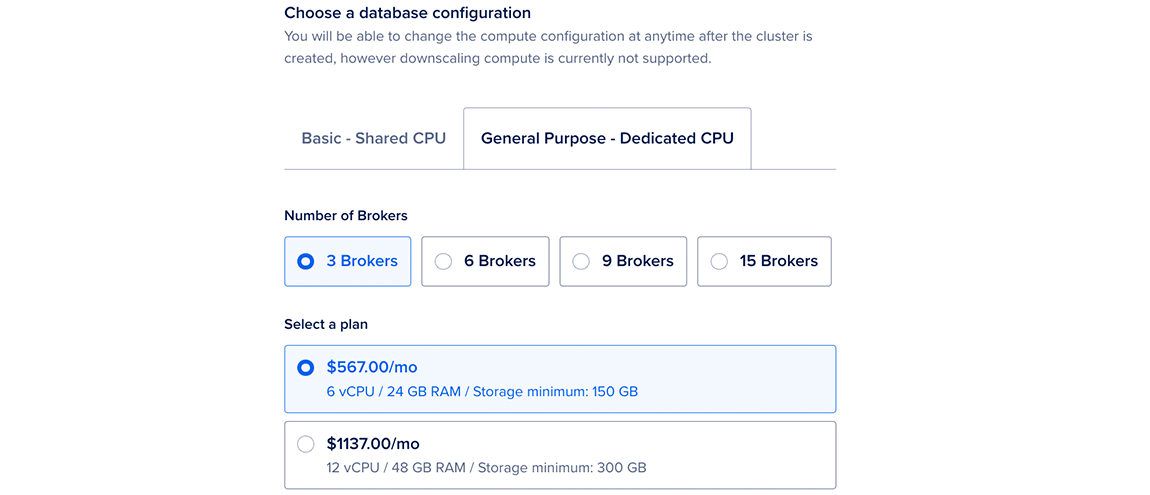
After creation, you can increase the number or size of database nodes at any time. However, you cannot downsize nodes to have less storage than the current storage the cluster is currently using.
Because Kafka is more resource-intensive than other engines, we recommend using shared CPU plans for development and testing workloads and using dedicated CPU plans for production workloads.
Choose a storage size
In the Choose a storage size section, you can increase your storage by clicking the up arrow or entering your desired storage amount, in increments of 10 GB, up to the maximum listed in the storage range. Additional storage you add to the cluster costs $0.21 per GiB per month.

You can increase or decrease your storage at any time.
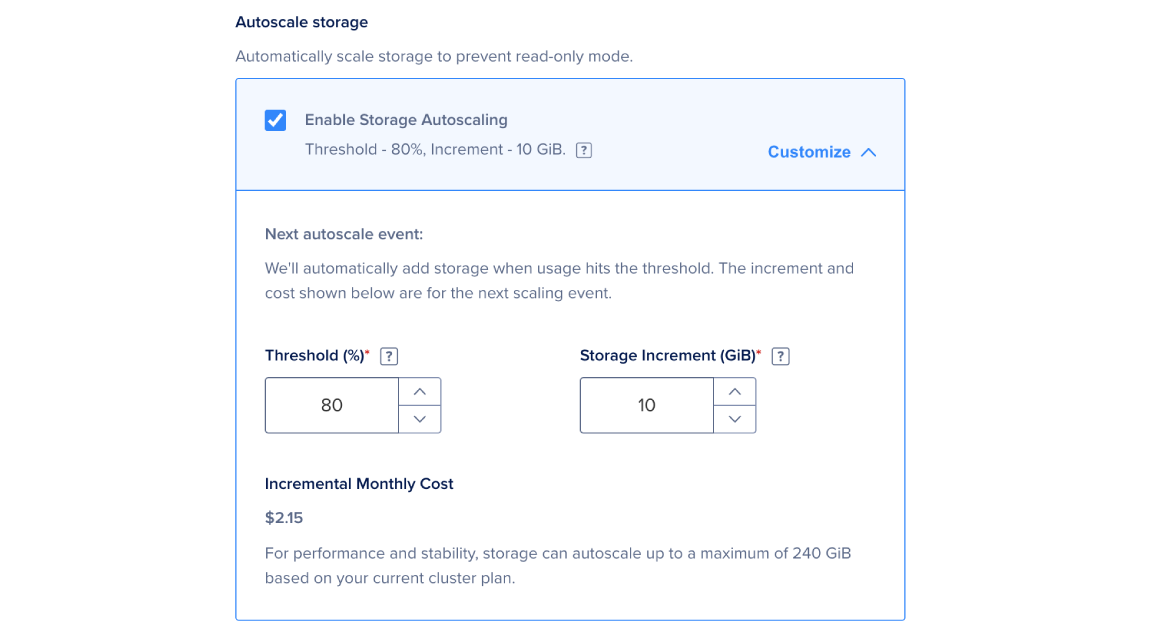
Enable storage autoscaling
The Autoscale storage section lets you check a box to automatically increase storage when disk capacity reaches a set percentage threshold. The system bills this increase as additional storage. If you click Customize, you can type your own percentage threshold and storage increment.
Autoscaling takes several minutes, depending on the cluster size. It runs without downtime, and you do not need to take any action.
Finalize and Create
In the last section, Finalize and Create, choose the name for the cluster, the project to add it to, and any tags you want to use.

There are three sub-headers in this section:
-
Choose a name: You can leave the automatically-generated name for the database or choose a custom name. Names must be unique, be between 3 and 63 characters long, and only contain alphanumeric characters, dashes, and periods.
-
Select a project: You can leave the default project or choose another one.
-
Tags: You can add a tag by typing it into the text box and pressing enter. Tags can only contain letters, numbers, colons, dashes, and underscores.
After creation, you can always edit the database’s tags or move it to another project; however, its name cannot be changed.
When you’re ready, click the Create a Database Cluster button.
Clusters typically take five minutes or more to provision, but you can complete important configuration tasks such as restricting inbound connections while you wait.