How to Mount Datasets in a Gradient Notebook
Last verified 22 Jan 2026
Notebooks are a web-based Jupyter IDE with shared persistent storage for long-term development and inter-notebook collaboration, backed by accelerated compute.
Mount Datasets in a Notebook
The dashboard supports mounting datasets for exploring data and training models. On the datasets tab, you can mount existing team datasets, public datasets, and create new team datasets.
You can mount a dataset by clicking the MOUNT button next to either the team or public dataset you want to use.
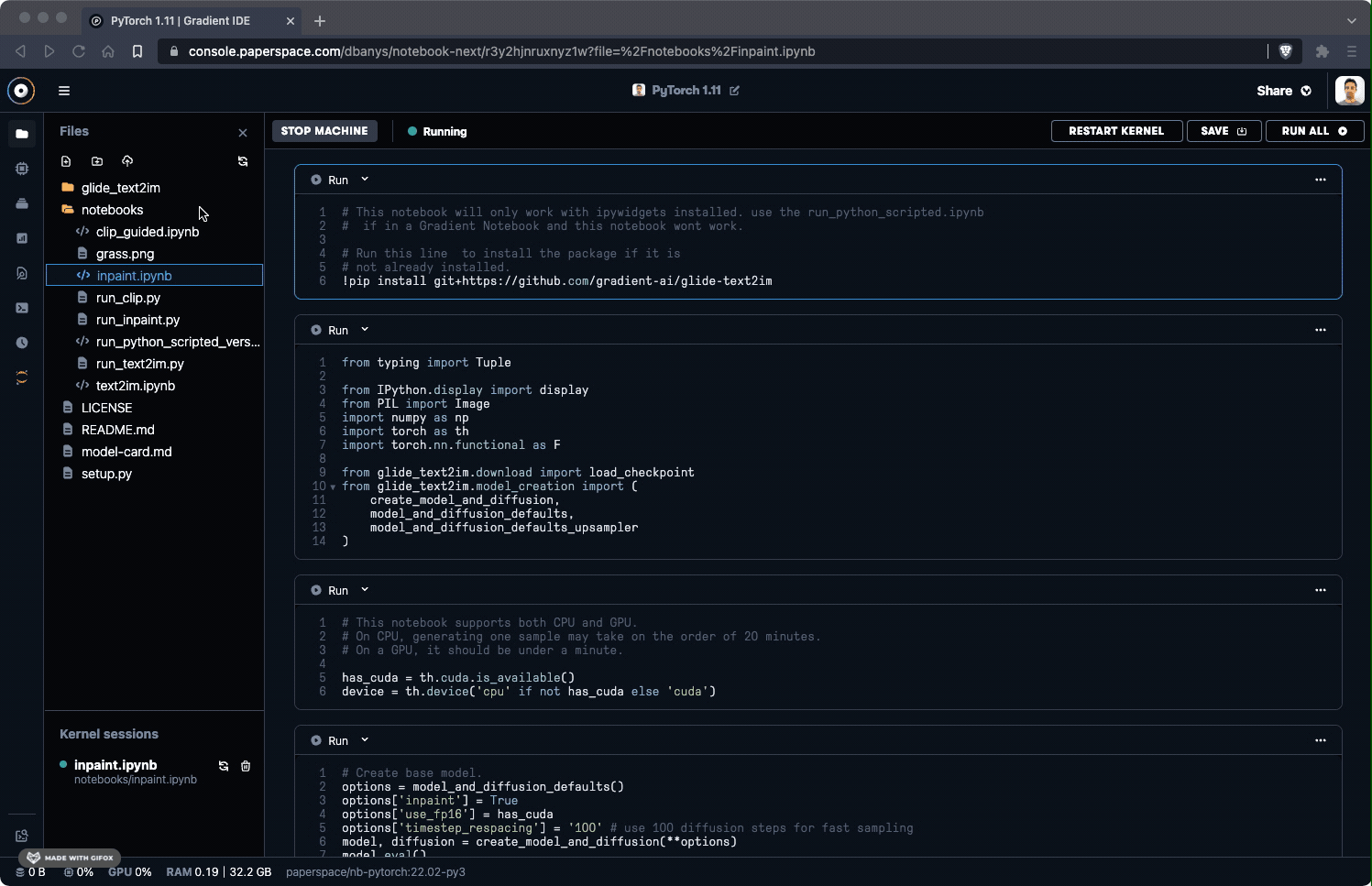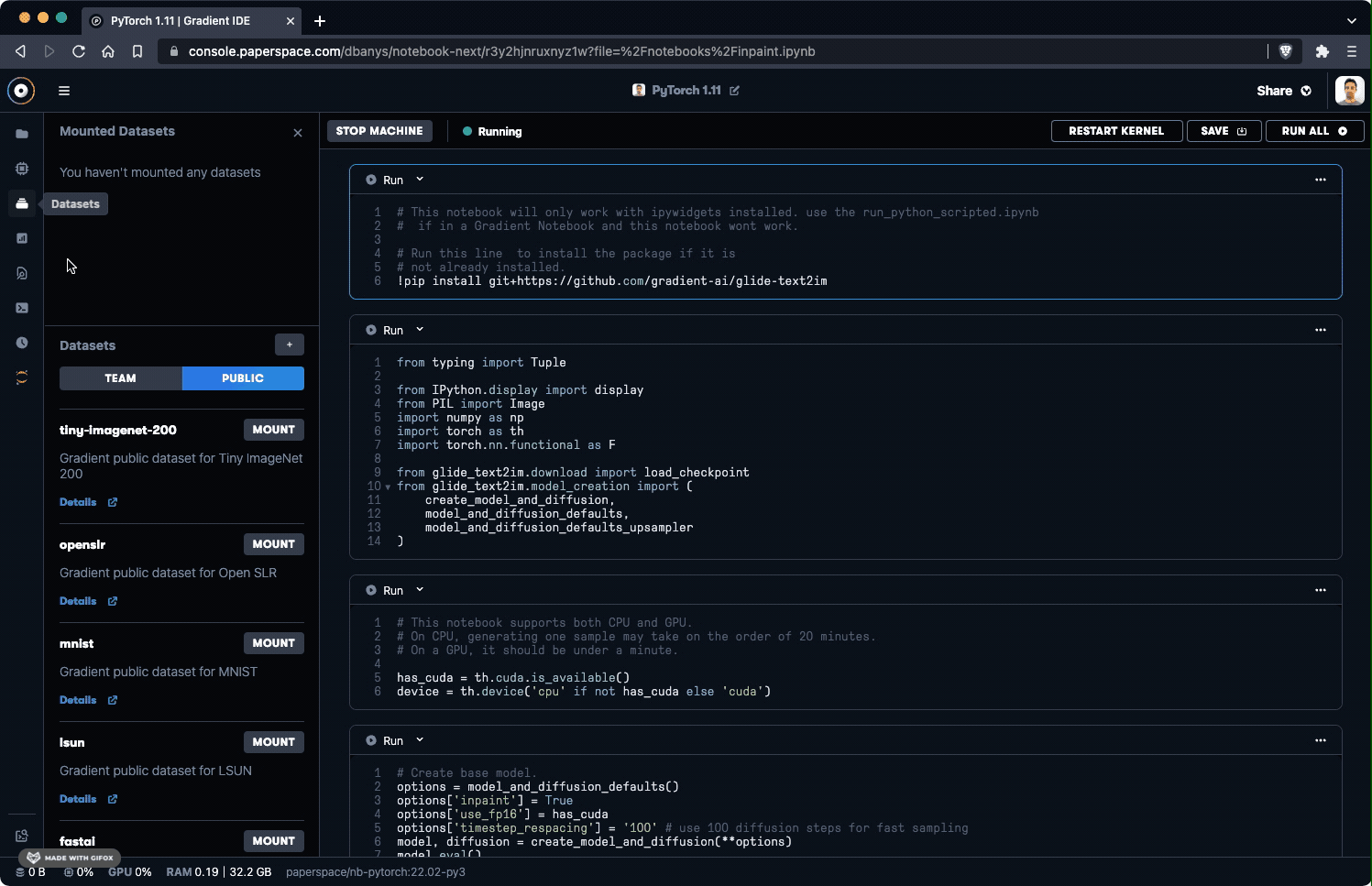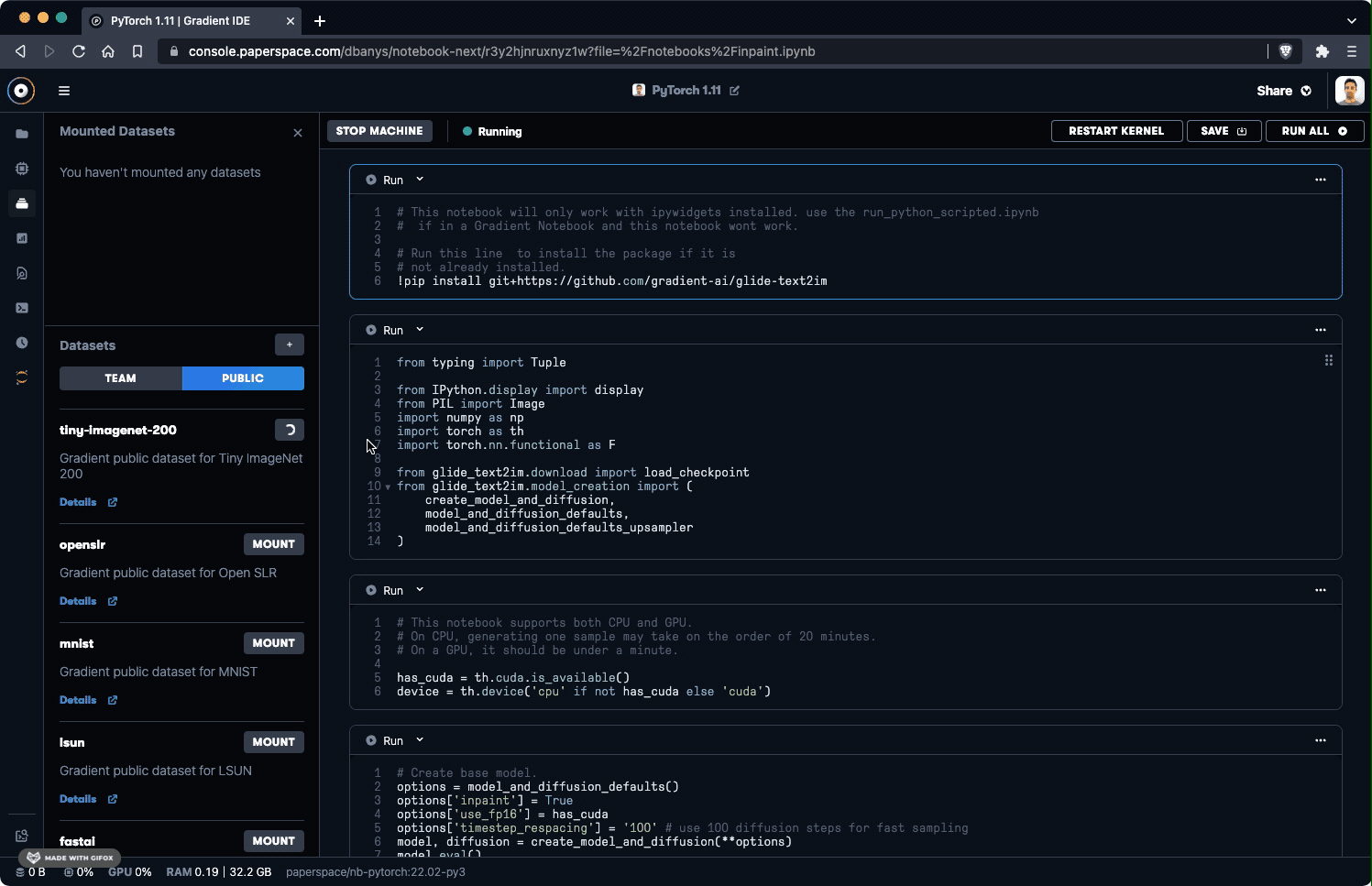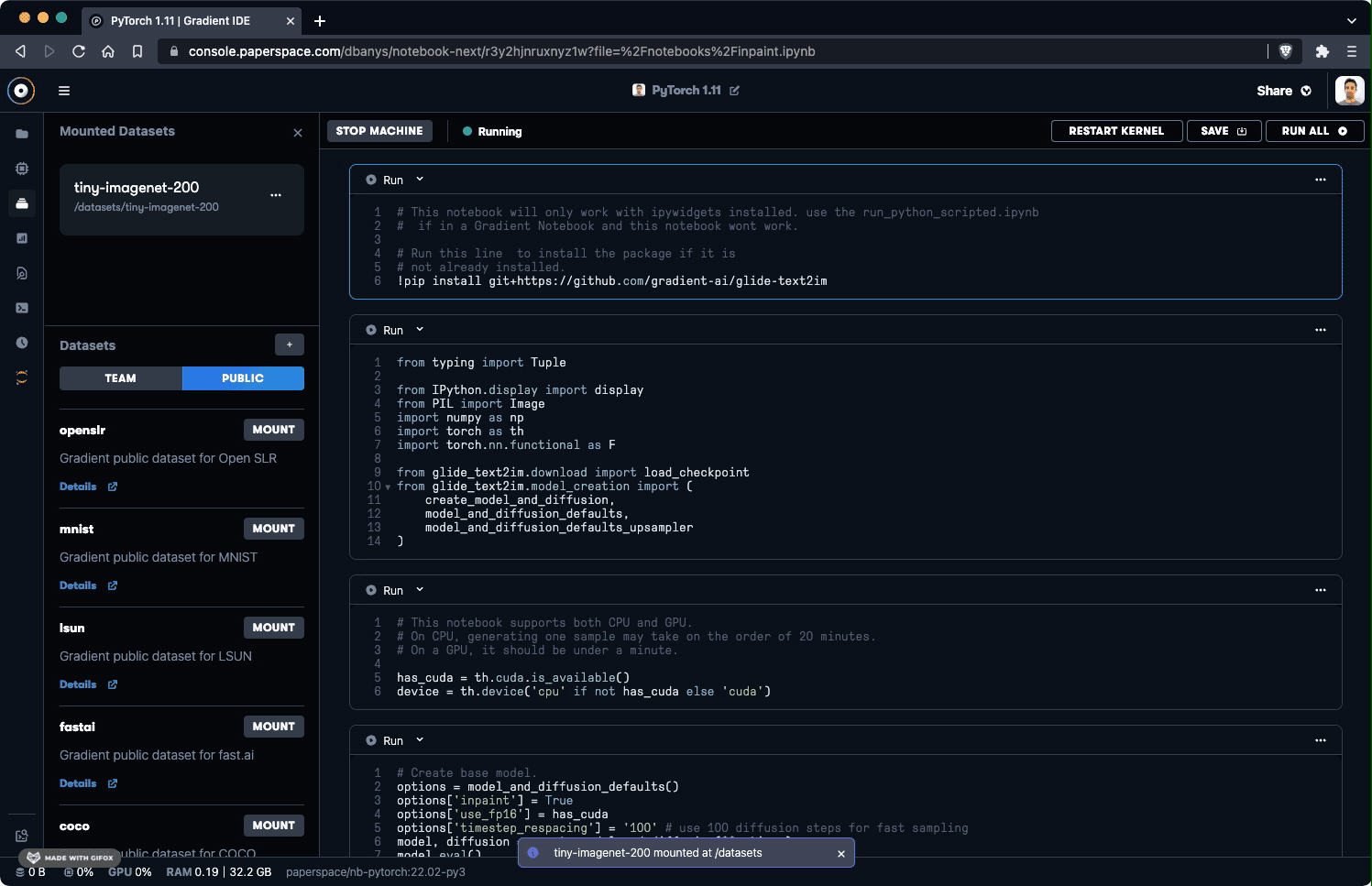
When mounting a team dataset, this only mounts the latest version of a dataset. You can change the version of the dataset in the Advanced Settings section.
Add Small Datasets to a Notebook
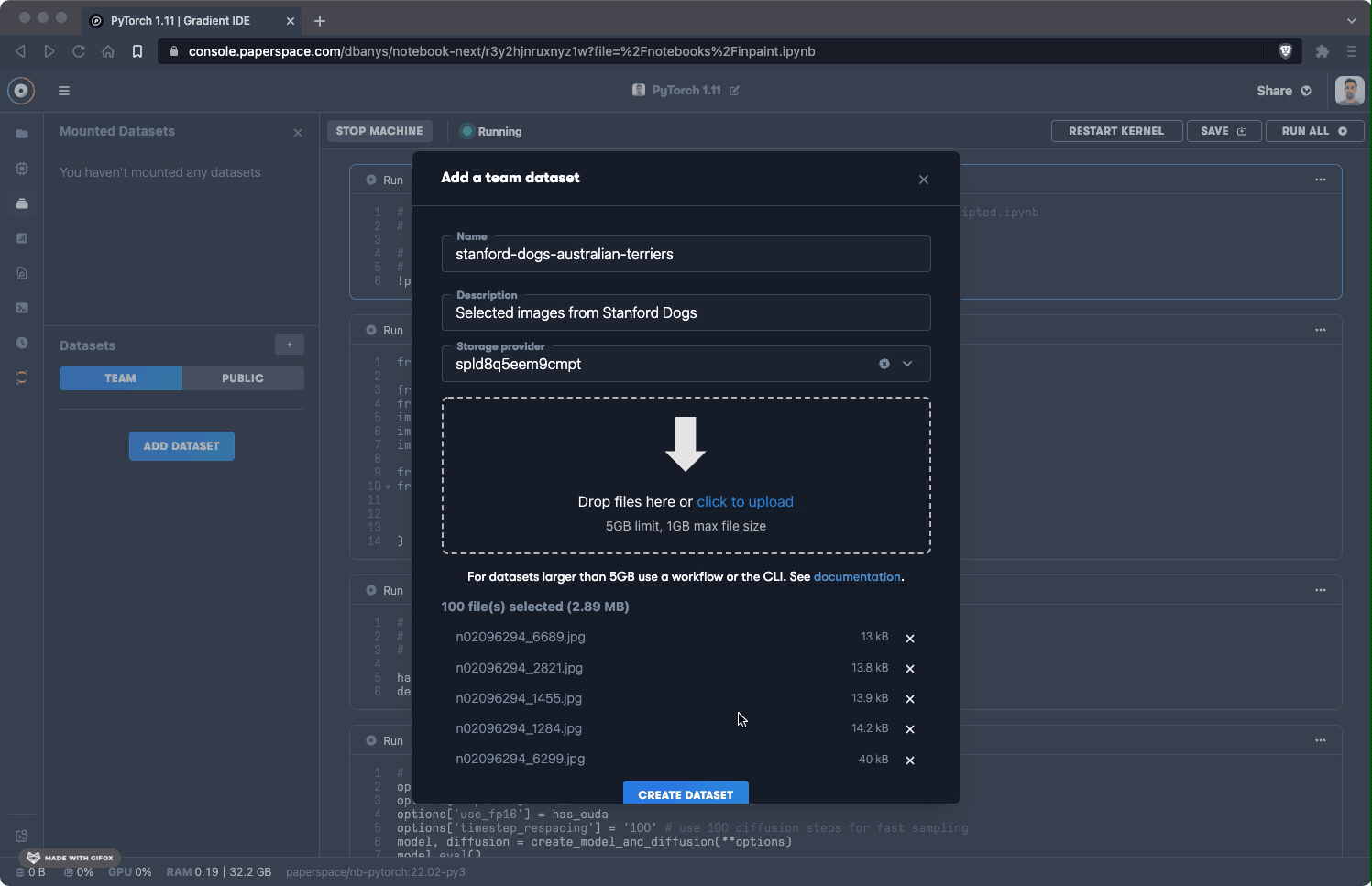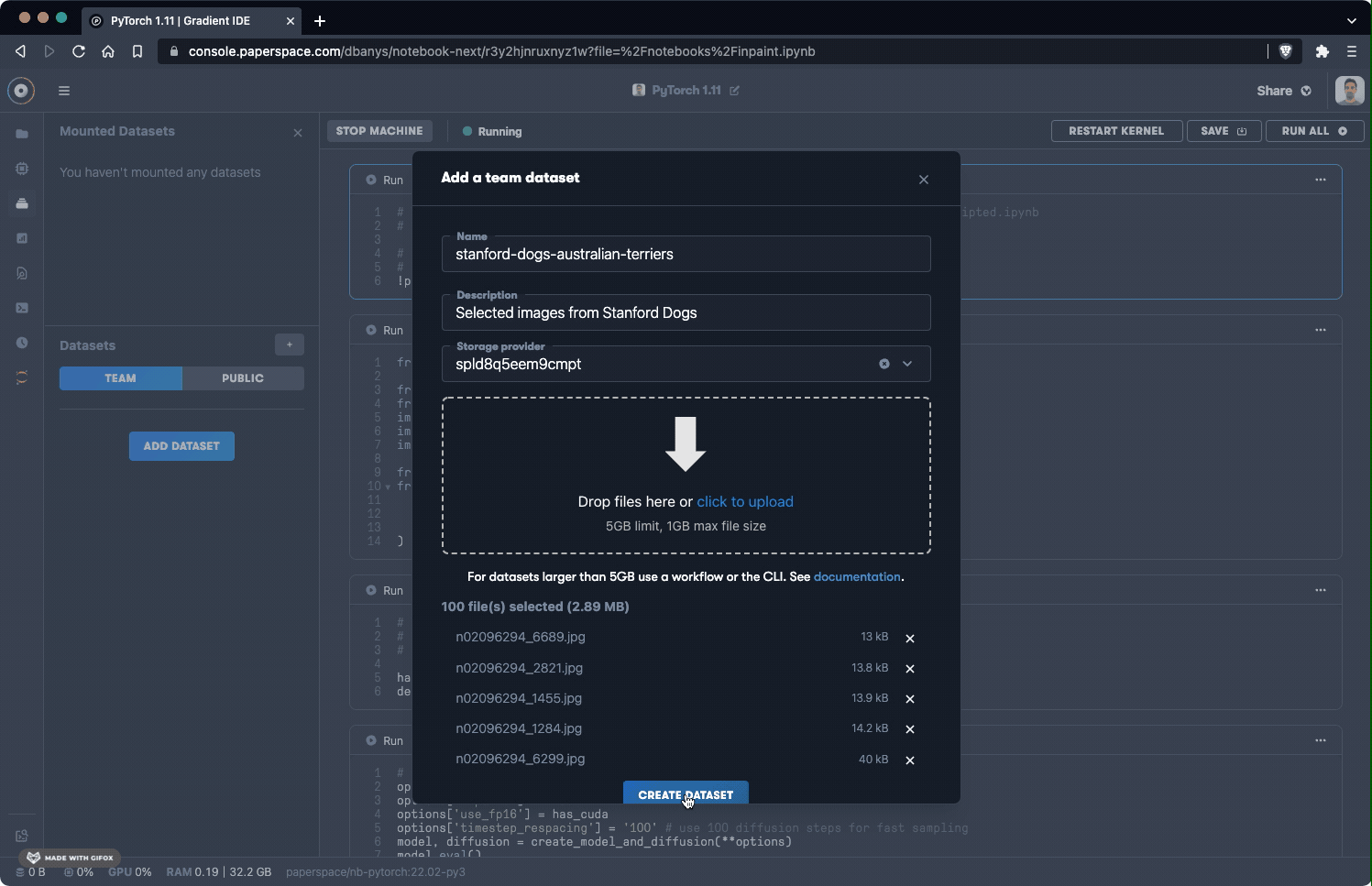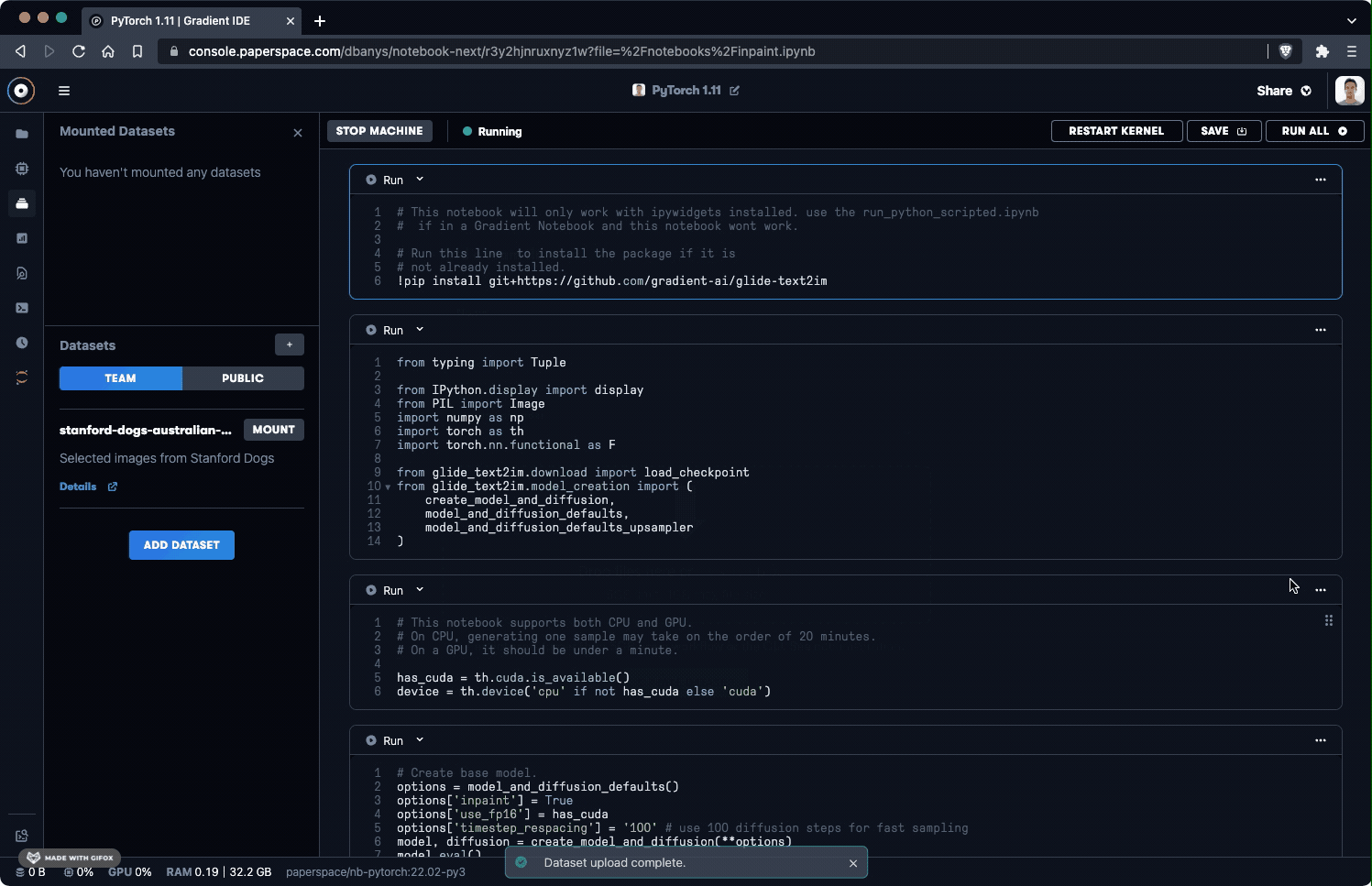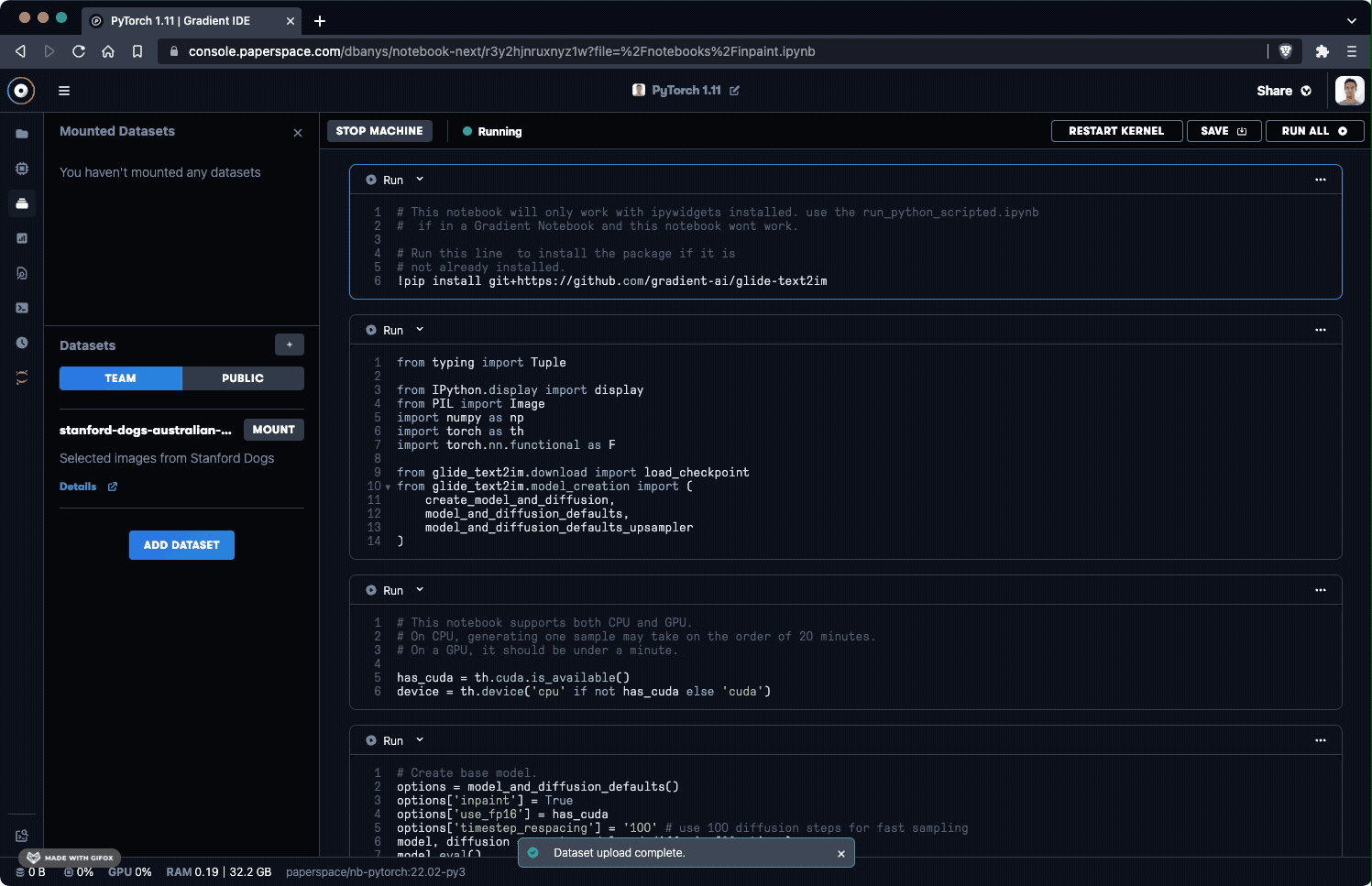
To add a new dataset, click the + icon, then name, describe, and upload the data. You can close the window once the upload has started, as the process continues to happen in the background.
Adding Large Datasets (5 GB+) to a Notebook
To create datasets larger than 5 GB, you can use the CLI through the terminal.
$ gradient datasets create --name democli --storageProviderId ssfe843ndkjdsnr
Created dataset: dsr5zdx0thjhfe2All Gradient datasets are versioned, so if you want to make any changes to data in a dataset, you need to create a new version. The following command creates a new version of your dataset.
$ gradient datasets versions create --id dst364npcw6ccok
Created dataset version: dst364npcw6ccok:fo5rp4mOnce the new version is created, you can then add files to the dataset version.
$ gradient datasets files put --id dst364npcw6ccok:fo5rp4m --source-path ./some-data/Once all your files are uploaded to the new version, commit the version to the dataset.
$ gradient datasets versions commit --id dst364npcw6ccok:fo5rp4m
Committed dataset version: dst364npcw6ccok:fo5rp4mOnce the dataset version is committed, the data is available in the UI, and you can reference it in other Gradient services such as Notebooks, Workflows, and Deployments.
Datasets Advanced Settings
To access the settings file that manages all mounted datasets, go to .gradient/settings.yaml where you can see all of the mounted datasets and their arguments. You should only use this file for the following:
If you want to change the version of the dataset that is mounted, you have to change the version-id of the dataset.
integrations:
quarterly-reports: # mounts in /datasets/quarterly-reports
type: dataset # denotes a paperspace dataset
id: dataset-id # a paperspace dataset id
version: version-id # a paperspace version id
my-bucket-data: # mounts in /datasets/my-bucket-data
type: s3 # an s3 bucket
url: s3://my-bucket/my-data # your s3 bucket url
accessKeyId: AK123 # your s3 access key id
secretAccessKey: secret:my-bucket-secret-key # a paperspace secret with your s3 secret key
region: "us-west-1" # the aws region your bucket is in, if not in aws set "endpoint"
endpoint: "https://my-bucket-host.com" # a custom bucket host, do not set region if set