The sliders and input fields in the control panel show recommended values for typical use. When you use the API or an SDK, you can set max_tokens, temperature, and top_p outside those recommended bounds. Each value is validated against the API’s server-side maximum. Values that exceed the slider ranges can increase per-request cost, produce incoherent or truncated output, or be clamped by the underlying model provider. These settings apply only to the resource you configure and do not affect model safety controls or other tenants.
Test and Compare Models Using the Model Playground
Last verified 13 Jul 2026
Inference provides a single control plane for managing inference workflows. It includes a Model Catalog where you can view available foundation models, including both DigitalOcean-hosted and third-party commercial models, compare model capabilities and pricing, use routing to match inference requests to the best-fit model, and run inference using serverless or dedicated deployments.
The Model Playground provides an interactive interface for testing and comparing foundation models before integrating them into your applications.
In the Model Playground, you can:
- Send prompts to different models and review their responses.
- Generate multimodal artifacts from supported models.
- Upload images from local storage.
- Adjust model parameters such as temperature and token limits.
- Compare outputs across models to evaluate quality and suitability.
- Explore which models best fit your use case.
You are prompted to confirm billing in the Confirm Standard Billing for Playground Usage window. After you confirm, usage is billed according to the pricing for the model playground.
The Model Playground is available for all foundation models. To use the playground, in the DigitalOcean Control Panel, click Model Catalog under INFERENCE in the left menu. Select a model and then click Launch Playground in the top-right of the model card. The Model Playground tab opens where you can test and compare different models.
Test Models
To test a foundation model, on the Model Playground page, select a model from the dropdown list. The playground displays a capability-driven model card to suggest what you can try with the model, instead of pre-filling a single example prompt. Each model card summarizes capabilities such as intended use, parameters, and context length to help you shape your request.
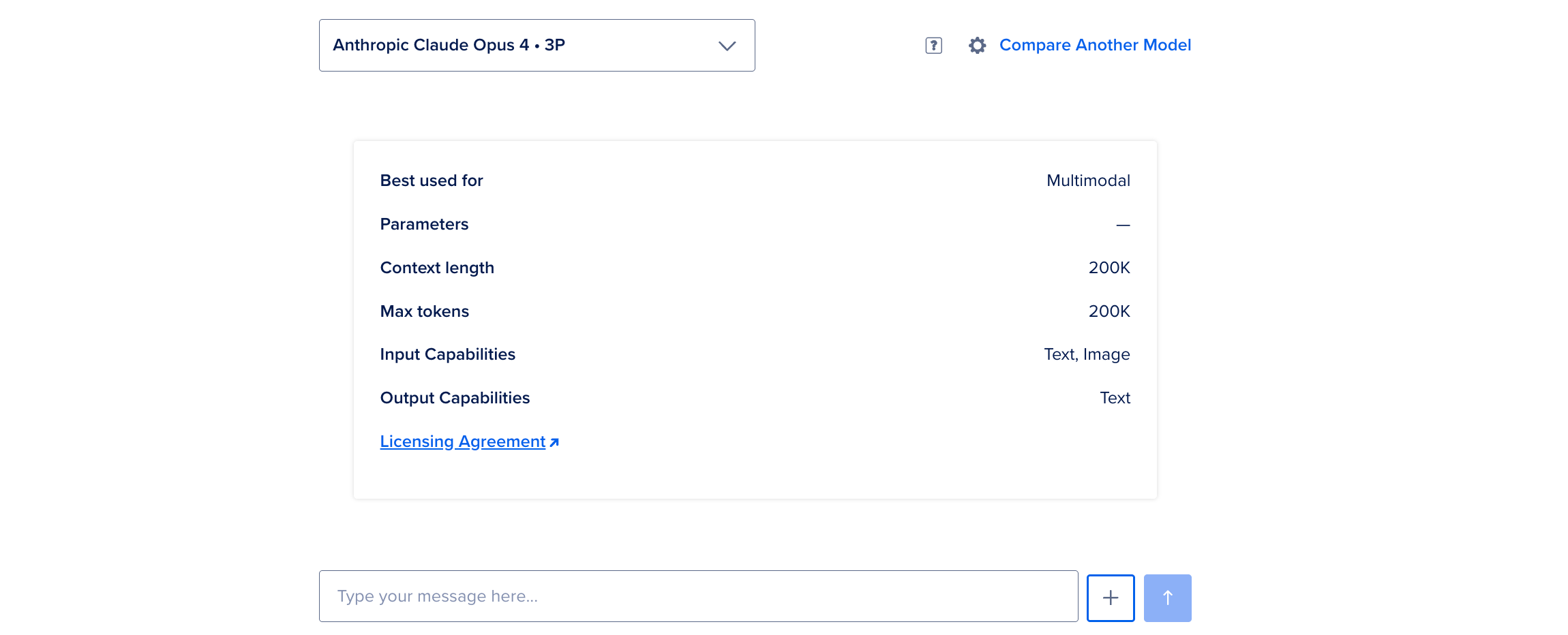
You can send text prompts and multimodal requests to generate audio, images, or text-to-speech when the model supports it. Type your question or request in the Type your message text box. To learn the best practices for how to write questions for the model, see Best Practices for Prompt Writing.
You can also add images to your prompt. Click + next to the input field. To upload an image from your local storage, select Upload File.
After the model responds, review the length, style, and speed of the output.
To adjust how the model behaves or to inspect API details, click the gear icon to open the model settings panel. Here, you can change model parameters and copy the API requests to interact with the model.
For text and reasoning models, you can adjust the number of tokens, temperature, and top p values. For multimodal models, you can adjust settings specific to each output type such as image resolution, aspect ratio, and number of images to generate, video resolution, frames per second, and motion strength to control how much the subjects or camera move within the scene, and audio duration, sample rate, and voice style:
| Model Type | Settings |
|---|---|
| Text | Max Tokens, Temperature, Top P |
| Reasoning (Anthropic, OpenAI, and other reasoning models) | Max Tokens, Temperature |
| Image | Max Tokens, Temperature, Resolution, Aspect Ratio, Number of Images |
| Video | Max Tokens, Temperature, Length (in seconds), Resolution, Frames Per Second, Motion Strength |
| Audio | Max Tokens, Temperature, Duration (in seconds), Sample Rate (in Hertz), Voice Style |
-
Max Tokens: Defines the maximum output tokens a model processes. For model-specific details, see the models page. The control panel slider shows a recommended range. Setting a value above what the selected model supports causes the value to be clamped by the model provider and can increase per-request cost.
-
Temperature: Controls the model’s creativity. Lower values produce more predictable and conservative responses, while higher values encourage creativity and variation. Values are rounded to the nearest hundredth. For example, if you enter a value of
0.255, the value is rounded to0.26. The control panel slider exposes the0to1recommended range. Values above1typically produce incoherent output and may be clamped by the underlying model provider. -
Top P: Defines the cumulative probability threshold for word selection. Higher values allow for more diverse outputs, while lower values ensure focused and coherent responses. Values are rounded to the nearest hundredth. For example, if you enter a value of
0.255, the value is rounded to0.26. The control panel slider exposes the0to1recommended range. Nucleus sampling is only meaningful for values within(0, 1]; values outside this range can produce undefined behavior.
Evaluate the responses and, if needed, keep adjusting the model settings until the behavior matches what you need.
Compare Models
To compare different foundation models, on the Model Playground page, click Compare Another Model to open the comparison view. Select a model from the dropdown list and toggle Sync Inputs so the same prompt and attachments apply to each model where supported.
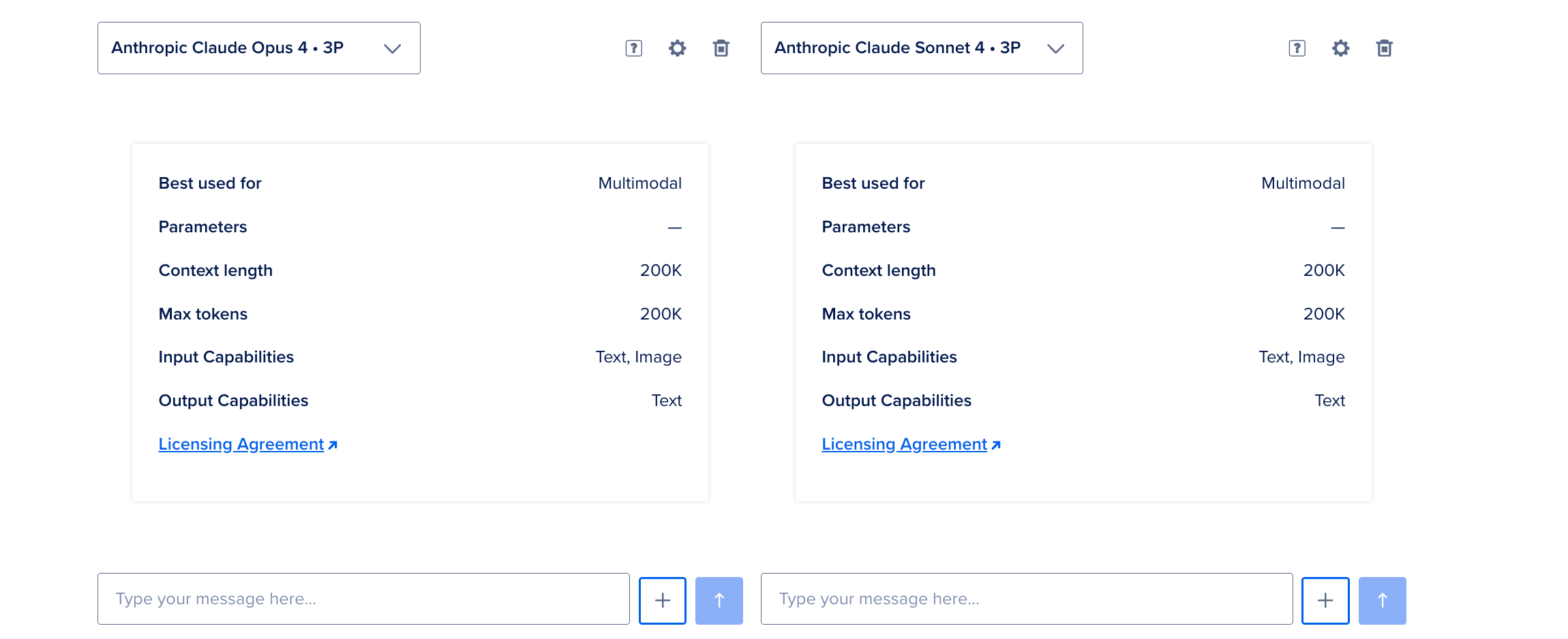
Enter your prompt in the text box, add attachments, and press Enter. Compare the responses, and adjust model settings in the model settings panel as needed.