How to Use Inference Routerpublic
Last verified 13 Jul 2026
Inference provides a single control plane for managing inference workflows. It includes a Model Catalog where you can view available foundation models, including both DigitalOcean-hosted and third-party commercial models, compare model capabilities and pricing, use routing to match inference requests to the best-fit model, and run inference using serverless or dedicated deployments.
Inference Router is available in public preview and enabled for all users. You can contact support for questions or assistance.
Inference Router lets you route serverless inference and dedicated inference requests to foundation models using rules. You can configure the routing rules to optimize for model cost or model latency. The router analyzes each prompt and sends each request to the best model suited for the job. Inference routing provides faster systems as well as lower costs.
You can select pre-configured routers or build your own router using the Control Panel or using the API.
How Inference Routing Works
A router is a collection of logically grouped tasks and fallback models. A task is a combination of a name, a description, and a model pool with selection policy. The task description and name define which model the router routes to based on the incoming query to the router. Each task has a pool of models and a policy for selecting among them, such as prioritizing the lowest cost or the lowest latency model.
You can choose from preset tasks or define your own custom tasks for specific use cases. Preset tasks have a pre-configured combination of eligible models across different providers and capability tiers in model pools, and a selection policy based on cost and latency that DigitalOcean has benchmarked and optimized. Model pools allow you to have more than one model per task. Default preset tasks have an Optimal selection policy, which is based on benchmarking done by DigitalOcean to determine the best model.
The router reads each incoming request, evaluates the request against the tasks configured in the router, and if it matches, it picks the right model from the model pool, while applying the selection policy to determine the best-fit model.
For custom routers, you can configure the router to skip the automated selection policy and specify a manual order of models to be tried sequentially. This manual override allows for precise control, ensuring that models are attempted in the exact sequence you specified.
To ensure system resiliency, each router incorporates a fallback mechanism. If, for some reason, the selected model is not available, down, or rate limited, the router picks the next best model. For example, if cost is the selection policy, it cycles through and picks the cheapest model, before the fallback models. These fallback models are also tried in a prioritized order, providing an instant and intelligent failover process that maintains session continuity without manual intervention.
Create Inference Router in the Control Panel
To create an Inference Router, in the DigitalOcean Control Panel, click INFERENCE in the left menu and select Inference Router. You can use a default router we provide to get started quickly or define a custom router.
Get Started Using Default Routers
To get started quickly, you can use a pre-configured router. In the Getting Started tab, click See Default Routers or select a Recommended Router. We provide pre-configured routers for tasks such as writing and content development, software engineering, and document intelligence. These provide one-click solutions for common agentic patterns, and are templatized policies that suggest models for specific use cases. You can see these routers on the My Routers page.
Preset router configurations and optimal model recommendations are derived from a hybrid evaluation methodology. For model selection, we combine Arena and Artificial Analysis leaderboard rankings to identify top candidates per route based on public benchmarks, then validate them through in-house benchmarking on task-specific datasets. Our dataset strategy draws from curated open-source datasets alongside proprietary task-specific datasets, with final recommendations validated by DigitalOcean’s data science team using a combination of automated scoring and human evaluation.
Build Custom Router
You can build your own router that defines specific use cases and policies. To create a custom router, on the top right of the Inference Router page, click Create Router to open the Create a Router page.
Name Your Router
In the Choose a unique name field, specify a name for the router.
Describe Your Router
In the Description field, add a description of what the router is for. The description is used as a routing prompt so that the router can choose the correct task for each request.
Define Tasks
Define the tasks to include in your router. In the Router Tasks section, you can define custom tasks or add pre-configured tasks:
Define Custom Tasks
Using custom tasks, you can customize the router selection policy and model combinations from scratch. In the Router Tasks section, click Add Custom Task from the Add Tasks dropdown list to open the Create Custom Task pane.
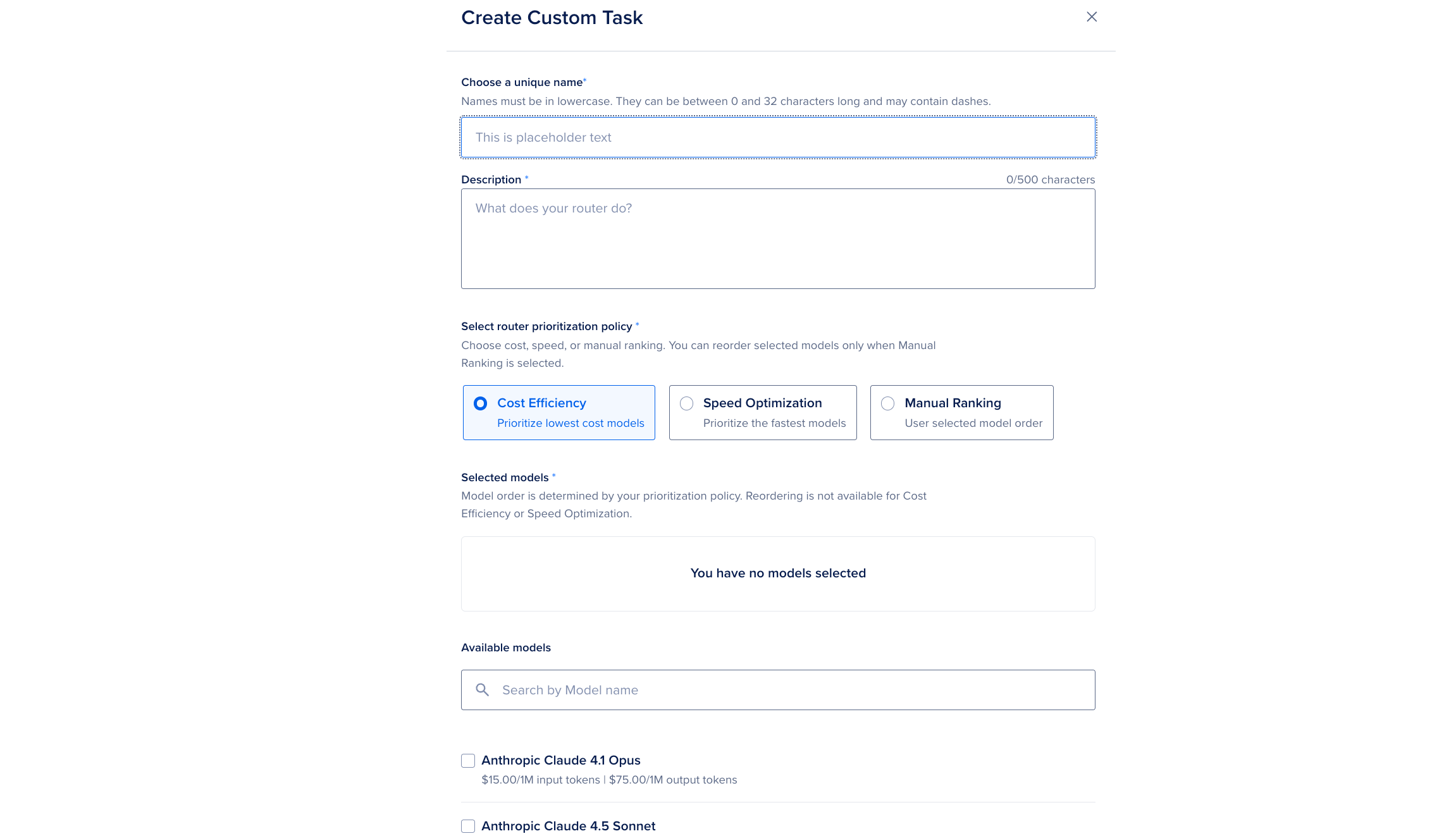
Specify the following values for the custom task:
-
Name and description for the task. Specify a name and description in the Choose a unique name and Description fields. The name and description you provide are important to match the intent for the router. See below for name and description recommendations.
-
Router prioritization policy. Select a policy in the Select router prioritization policy field. You can choose one of the following:
- Cost Efficiency: Token costs for the models in the pool
- Speed Optimization: Time for first token on DigitalOcean based on Time To First Token (TTFT)
- Manual Ranking: Order in which you added the models to the pool
-
Models to use for the routing. Select models to use for routing in the Selected models section. Make sure to select the models in the order you want the router to use them. Model reordering is only available for Manual Ranking. You can select up to 3 models in the model pool. Models supported for Dedicated Inference are displayed only when the selection policy is Speed Optimization or Manual Ranking.
Custom Task Best Practices
We recommend the following when creating custom tasks:
-
Consistent naming: Align route names with their descriptions.
Prefer Avoid {"name": "quadratic_equation", "description": "solving quadratic equations"}{"name": "math", "description": "handle solving quadratic equations"} -
Clear usage description: Make your route names and descriptions specific, unambiguous, and minimize overlap between routes. The Router has improved performance when it can clearly distinguish between different types of requests.
Prefer Avoid {"name": "math", "description": "solving, explaining math problems, concepts"}{"name": "math", "description": "anything closely related to mathematics"} -
Noun-centric descriptors: Preference-based routers offer more stable and semantically rich signals for matching, thus providing improved performance.
Click Save. The tasks are displayed in the Router Tasks section.
Add Pre-configured Tasks
Pre-configured tasks have a combination of models and selection policy that DigitalOcean has configured, benchmarked, and optimized. Preset tasks are built on a hybrid evaluation approach combining public benchmark signals from Arena and Artificial Analysis with in-house benchmarking across curated task-specific datasets, validated by DigitalOcean using human evaluation.
We provide a variety of pre-configured tasks, such as for summarizing long documents, text extraction, code generation, and bug fixing.
Click Add Task from the Add Tasks dropdown list to open the Add Tasks panel.
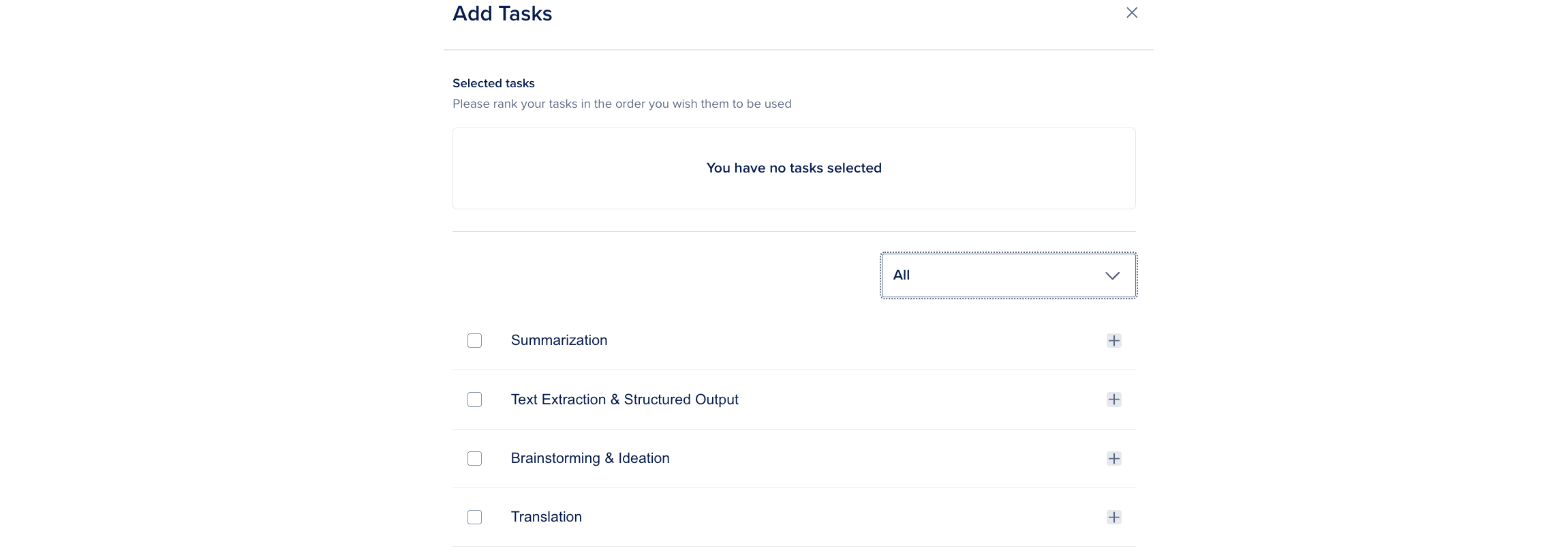
You can click the + next to the task name to view the task description, model pool, and selection policy. Select the tasks that suit your use case and then click Save. The selected tasks are displayed in the Router Tasks section.
You can optionally modify a preset task by clicking Edit. In the Edit Task pane, modify the task name, description, selection policy, and selected models. You can select up to three models in the model pool and choose one of the following as the selection policy:
- Optimal: Based on hybrid evaluation approach combining public benchmark signals with DigitalOcean’s in-house benchmarking across curated task-specific datasets
- Cost Efficiency: Token costs for the models in the pool
- Speed Optimization: Time To First Token (TTFT) of the models on DigitalOcean
Then, click Save.
Specify Fallback Models
Requests are routed to fallback models when the request does not match any of the configured tasks. In the Fallback Models section, click Add Fallback Models to open the Select Fallback Models panel. Make your selections from the model list. You can also reorder the models by clicking on the right of the selected model and dragging it. Then, click Save.
Create Router
Click Create Router to create the custom router. After the creation completes, the router is displayed in the My Routers tab.
Create Inference Router Using Automation
To create a custom router using the DigitalOcean API, send a POST request to /v2/gen-ai/models/routers. Define the following schema for the router and pass it in the cURL request:
curl -X POST "https://api.digitalocean.com/v2/gen-ai/models/routers" \
-H "Authorization: Bearer $DIGITALOCEAN_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "my-test-router",
"description": "my-test-router",
"policies": [
{
"task_slug": "translation",
"selection_policy": {
"prefer": "cheapest"
}
},
{
"custom_task": {
"name": "summarization",
"description": "Summarize documents"
},
"models": ["openai-gpt-5.2", "glm-5"],
"selection_policy": {
"prefer": "fastest"
}
}
],
"fallback_models": [
"openai-gpt-oss-120b"
]
}'Use the Router
To use the router, send prompts as described in Chat Completions or Responses, using the router name prefixed with router: in the model field in the request body. Using a router is a drop-in replacement for any model call. For example:
curl --location 'https://inference.do-ai.run/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $MODEL_ACCESS_KEY" \
--data '{
"model": "router:test-router",
"messages": [
{
"role": "user",
"content": "Are there any syntax issues here? Code: \nPython \nprices_usd = {'\''laptop'\'': 1200, '\''mouse'\'': 25, '\''monitor'\'': 300, '\''cable'\'': 12} \nexchange_rate = 0.92 \n# The line below is the focus \nexpensive_items_eur = {k: v * exchange_rate for k, v in prices_usd.items() if v > 50} \nprint(expensive_items_eur)"
}
],
"stream": true
}'You can get a model access key to use in your request, as described in Model Access Keys and set it as an environment variable by running the following command:
export MODEL_ACCESS_KEY="<your_model_key>"You can see which model your request routed to in the response:
data:
{
"choices": [
{
"delta": {
"content": null,
"reasoning_content": null,
"refusal": null,
"role": "assistant"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"created": 1775481301,
"id": "",
"model": "openai-gpt-oss-120b",
"object": "chat.completion.chunk"
}You can also view which task was ultimately selected in the response header x-model-router-selected-route:
x-model-router-selected-route: fallbackTest Router Performance
You can test the router against a model or another router in the playground. In the My Routers tab, click the … menu for the router you want to test. In the Compare section, choose the model to compare the router with. The Playground tab opens in a comparison view with the selected model and the router. In the text box, enter your question and press Enter. Compare the results which show cost difference, end-to-end latency, and the model selected for the router along with the specific task that was matched for the query. You can also click on the information icon next to Inference Router to quickly review the router configuration.
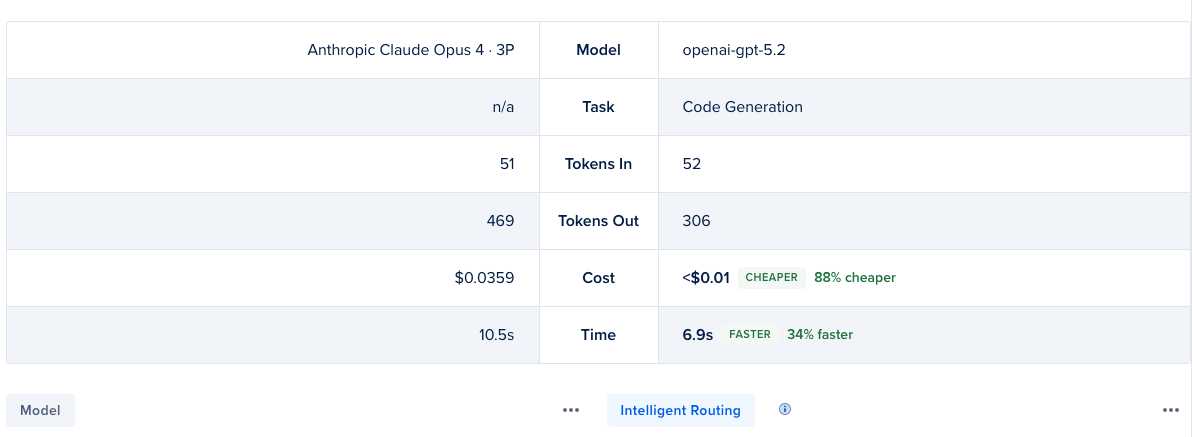
Using a router adds approximately 200ms of latency overhead.
Analyze Router Performance
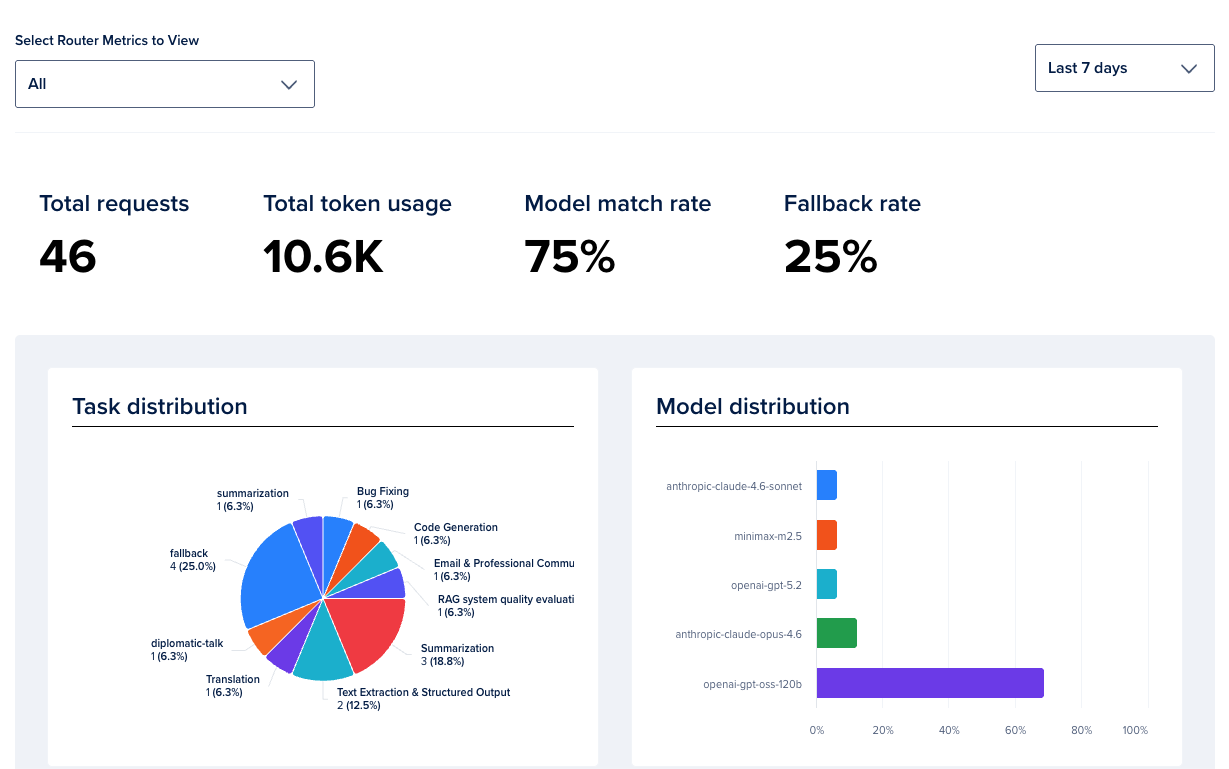
In the Analyze tab, you can view aggregate metrics across all routers or for specific routers. You can view the following metrics:
- Total Requests: Total requests that routers received
- Total token usage: Total tokens (input and output) used by models
- Model match rate: Percentage of requests that were matched by one of the tasks configured within the router
- Fallback rate: Percentage of requests that were not matched by one of the tasks configured within the router and had to fall back to a configured fallback model.
Test Router Accuracy
In the Playground tab, select Router Evaluation. Upload your dataset and click Evaluate. Evaluation runs in a few minutes using LLM-as-a-Judge scoring.
Once the evaluation completes, you can see the following metrics:
- Completeness: Measures how thoroughly the response covers key details from the provided prompt.
- Correctness: Measures accuracy of the response against expected output. High scores indicate likely accuracy; low scores indicate possible hallucinations or errors.
- Tokens Used: Total token consumption per request
- Latency: Average and P95 response time
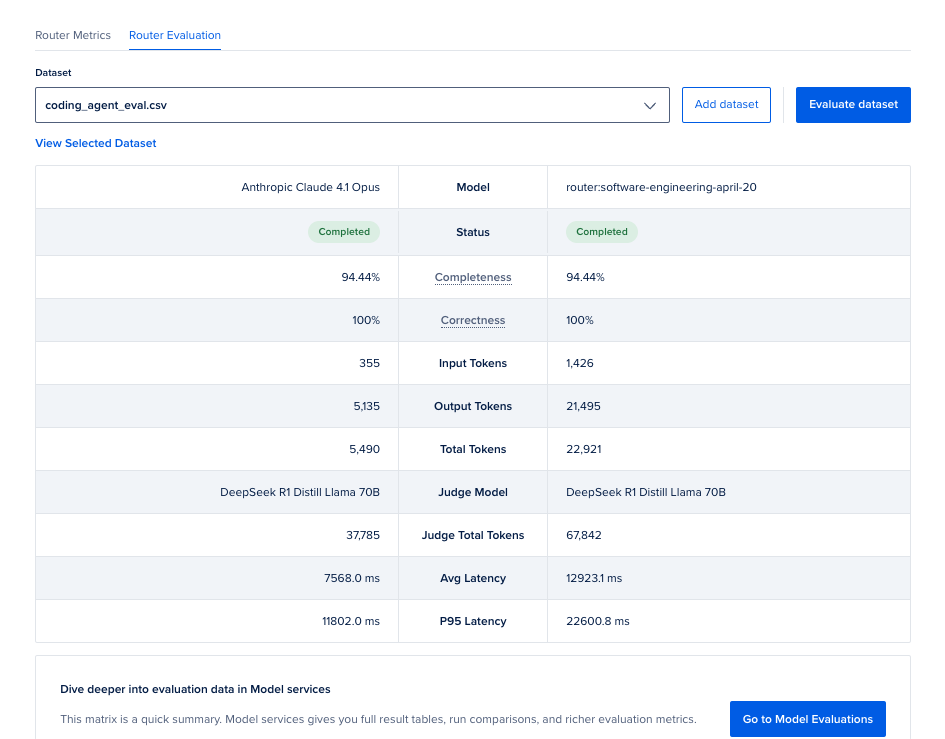
See more details about these metrics on the Evaluations page.
Edit, Duplicate, or Delete a Router in the Control Panel
In the My Routers tab, click the … menu next to the router. To update the router, select Edit Router to open the Edit a Router page. Make your updates and then click Update Router.
To duplicate an existing router, click Duplicate Router to open the Create a Router page. Update the router configurations and click Create Router.
To delete a router, click Delete Router. In the Delete Router window, enter the name of the router and click Delete.
Use Model Affinity for Caching
In agentic loops, successive prompts look different. For example, the model calls a tool first, then reasons about the results, and then writes the code. During the process, the router may switch models mid-session, which can cause the following problems:
- Behavioral inconsistency: Different models have different output styles and tool-calling formats. Switching mid-loop breaks agent parsing and produces incoherent responses.
- KV cache invalidation: Model providers use prefix-based KV caching. If the same token sequence hits the same model, cached attention state is reused. Switching models means full recomputation on every turn, which invalidates the cache for all subsequent turns.
- Cost impact on input tokens: Cached input tokens are cheaper. In a 15-turn loop where 90% of the input is cached prefix, this leads to 45-80% savings on input token cost. Switching models means zero cache hits, resulting in full price every turn.
By sending an X-Model-Affinity header with a session identifier from the client, you can make the router route the first request normally and then cache the result. All subsequent requests with the same affinity ID skip routing and use the cached model.
The following example shows how to use model affinity for caching. In the first call, routing is used. In the second call, a pinned session is used and routing is skipped.
echo "--- 7. Session pinning - first call (fresh routing decision) ---"
echo ""
curl --location 'https://inference.do-ai.run/v1/chat/completions' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "X-Model-Affinity: demo-session-001" \
-d '{
"model": "router:test-router",
"messages": [
{"role": "user", "content": "Write a Python function that implements binary search on a sorted array"}
]
}' | python3 -m json.tool
echo "--- 8. Session pinning - second call (same session, pinned) ---"
echo " Notice: same model returned with \"pinned\": true, routing was skipped"
echo ""
curl --location 'https://inference.do-ai.run/v1/chat/completions' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "X-Model-Affinity: demo-session-001" \
-d '{
"model": "router:test-router",
"messages": [
{"role": "user", "content": "Now explain how merge sort works and when to prefer it over quicksort"}
]
}' | python3 -m json.tool
echo ""