Basic - Shared CPU configurations only support one node. Use General Purpose - Dedicated CPU or Memory-Optimized - Dedicated CPU if you need a multi-node cluster.
How to Create an OpenSearch Vector Database Cluster
Last verified 15 Jul 2026
DigitalOcean Managed OpenSearch for vector search uses the same managed OpenSearch engine available under Managed Databases. It bundles the k-NN, ML Commons, and Neural Search plugins for vector similarity search, hybrid vector and keyword search, and remote embedding models.
OpenSearch vector database clusters use the same managed OpenSearch engine as DigitalOcean Managed Databases. OpenSearch includes the k-NN, ML Commons, and Hybrid Search plugins, so you can create vector indexes and run similarity queries after the cluster is active.
Create a Database Cluster Using Automation
You can create a vector database cluster using the DigitalOcean CLI (doctl) or the API.
Create a Database Cluster via CLI
To create a vector database cluster using doctl, you need to provide values for the --engine, --region, and --size flags. Use the doctl databases options engines, doctl databases options regions, and doctl databases options slugs commands, respectively, to get a list of available values.
The --wait flag waits until the cluster is online and prints the connection string.
After the cluster is online, add a trusted source so clients can connect to it:
To view the cluster’s connection details, use:
For the full command reference, see doctl databases.
Create a Database Cluster via API
To create a vector database cluster using the API, you need to provide values for the engine, region, and size fields, which specify the database’s engine, its datacenter, and its configuration, including the number of CPUs, amount of RAM, and disk size. Use the /v2/databases/options endpoint to get a list of available values.
The response includes the cluster ID, connection details, and a status field. Send a GET request to check the cluster status until it changes from creating to online.
After the cluster is online, add a trusted source so clients can connect to the cluster.
To add a trusted source, use the database firewall endpoint and provide the cluster ID and the trusted source type, such as an IP address, Droplet, Kubernetes cluster, App Platform app, or tag:
To retrieve the cluster’s connection details, send a GET request:
The response includes connection information such as the host, port, username, and password.
For all supported parameters, see the Databases API reference.
Create a Vector Database Cluster Using the Control Panel
To create a vector database cluster, go to the Vector Databases page, and then click Create Vector Database. Or click Create at the top of any page and choose Vector Database from the Data Services section of the menu.
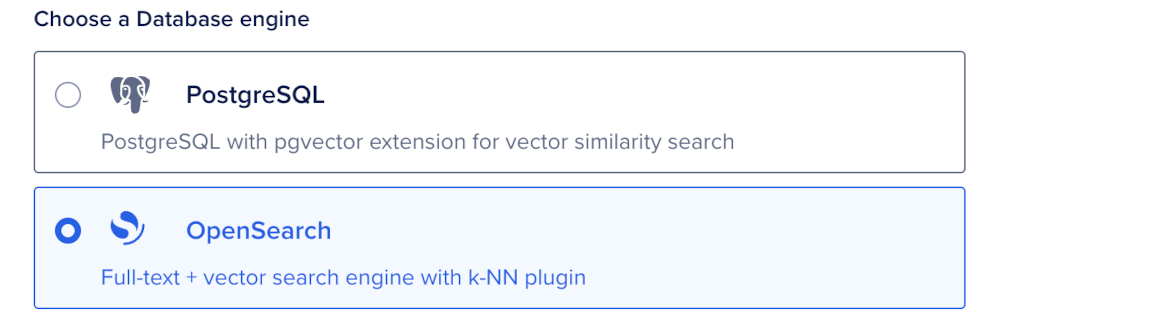
Choose a Database Engine
On the Create Database Cluster page, in Choose a database engine, select OpenSearch. The database engine and version can’t be changed after creation.
Choose a Database Configuration
In the Choose a Database Configuration section, select a database configuration for the cluster.
Vector workloads are often memory-bound. OpenSearch stores the HNSW graph in memory outside the JVM heap, and query latency can increase sharply when the graph no longer fits in RAM.

Choose a configuration based on your expected vector count, vector dimensions, metadata size, and query load:
- Basic - Shared CPU: Use for development, testing, and small vector workloads that don’t need consistent CPU performance.
- General Purpose - Dedicated CPU: Use for small-to-medium vector workloads that need predictable CPU performance, such as staging or production workloads with moderate query volume.
- Memory-Optimized - Dedicated CPU: Use for larger vector datasets, higher-dimensional vectors, or high-query-volume workloads where the HNSW graph needs more memory.
You can change the database configuration after creating the cluster, but downsizing isn’t supported.
Choose CPU Options
In the CPU options sub-section, select a CPU type. Available CPU options depend on the selected configuration and region:
- Regular (Disk: SSD): Use for standard workloads that don’t require NVMe-backed disk performance.
- Premium AMD (Disk: NVMe): Use for workloads that benefit from faster local disk performance. This option isn’t available for General Purpose - Dedicated CPU or Memory-Optimized - Dedicated CPU configurations.
- Premium Intel (Disk: NVMe): Use for workloads that benefit from faster local disk performance and predictable CPU performance.
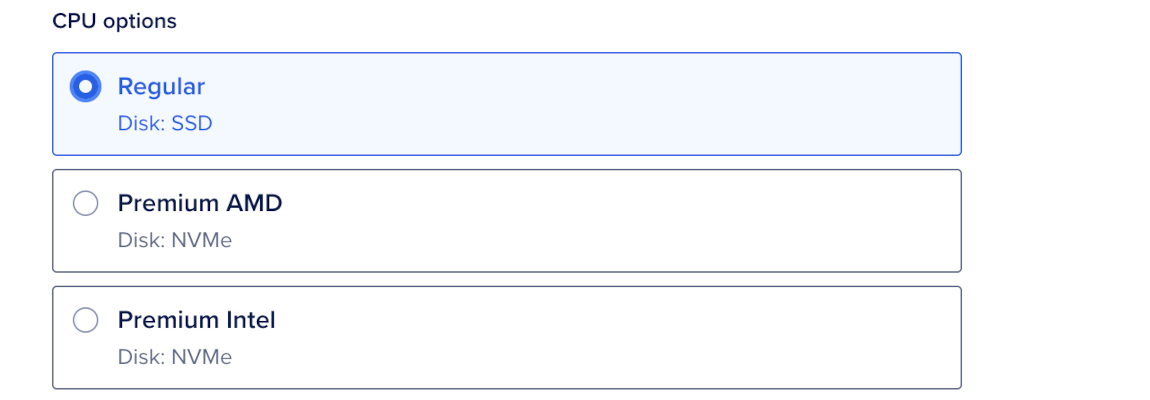
Premium CPUs use NVMe disks and can provide better performance for workloads with heavier indexing or query activity.
Select a Plan
In the Select a plan sub-section, choose the plan size for the cluster.
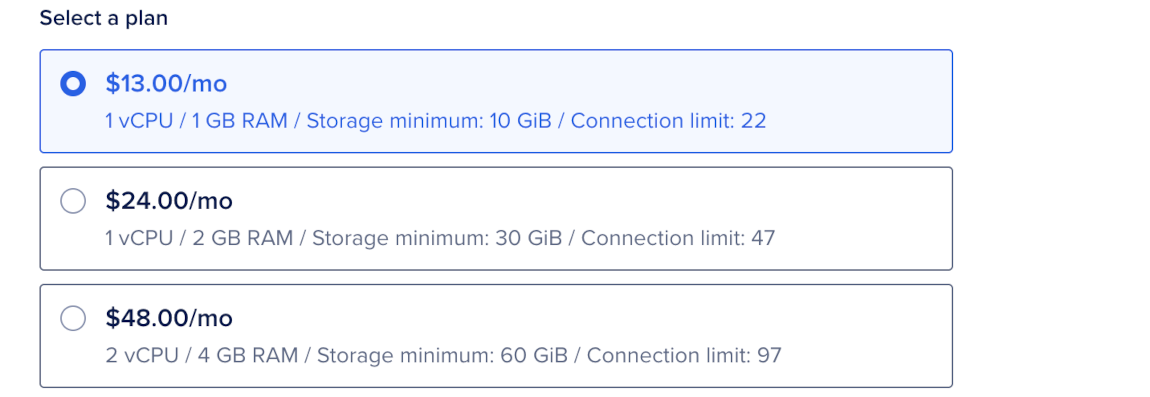
The plan determines the cluster’s vCPUs, RAM, and minimum storage. For vector workloads, choose a plan with enough RAM to hold the vector index, graph overhead, JVM heap, and operating system cache.
The vector itself uses four bytes per dimension. The HNSW graph uses extra memory for each vector’s graph connections. When each vector can have up to 16 connections, the graph adds about 128 bytes per vector.
Add a 20-30% safety margin for JVM heap, operating system page cache, metadata, source documents, Lucene segments, and workload growth.
OpenSearch supports multiple k-NN engines, including Faiss, Lucene, and NMSLIB. Faiss and Lucene are the recommended engines for new vector workloads. NMSLIB exists primarily for compatibility with older indexes.
If you expect your vector dataset to grow significantly, choose a larger plan before indexing large volumes of data. Resizing later may require reindexing or additional migration work, depending on your index design and workload.
Choose the Number of Nodes
In the Number of Nodes sub-section, select the number of nodes for the cluster: 1 Node, 3 Nodes, 6 Nodes, 9 Nodes, or 15 Nodes.

For specific workloads:
- Use a single-node cluster for development or small production workloads that don’t require high availability.
- Use at least three nodes for production workloads that need automated failover. OpenSearch replicates primary shards across nodes to tolerate a node failure without data loss.
Choose a Datacenter Region
In the Choose a Datacenter region section, select a region for the cluster.
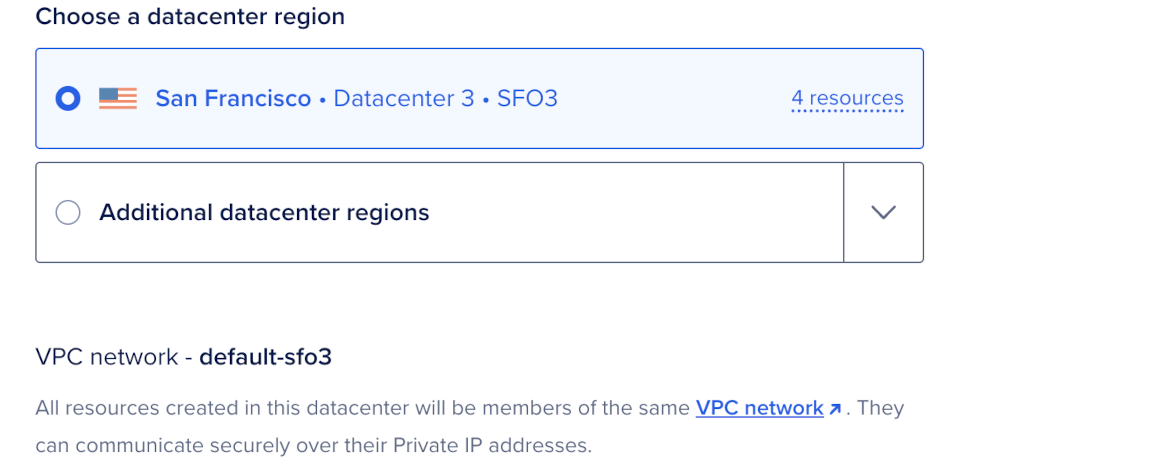
Choose the same region as the application that sends queries to the cluster. Cross-region latency can increase vector query time. For available regions, see Regional Availability.
The cluster uses the default VPC network for the selected datacenter region. Resources in the same VPC network can communicate securely over private IP addresses.
Each region has one or more datacenters, each with its own VPC network. Keeping resources in the same datacenter ensures they share the private networking interface, which reduces latency and prevents traffic from being routed over the public internet.
Finalize and Create
In the Finalize and create section, configure the cluster name and project.
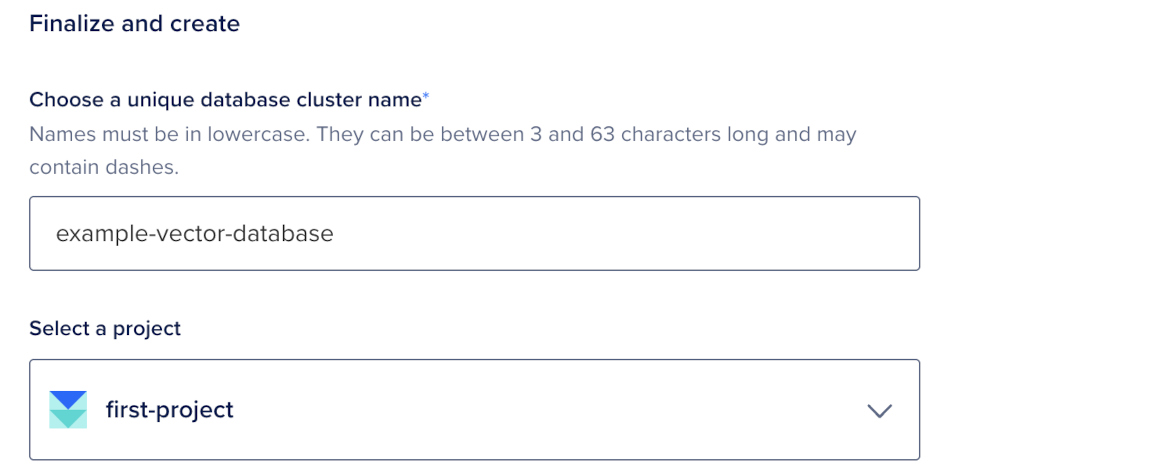
In the Choose a unique database cluster name field, either use the generated name or enter a unique name. Names must be lowercase, between 3 and 63 characters long, and can contain dashes.
From the Select a project dropdown menu, choose the project for the cluster.
Optionally, add tags to organize your cluster for billing and reporting.
Review Cost
In the Total monthly cost section, review the estimated monthly and hourly cost for the cluster, including compute, storage, autoscale increment, and autoscale threshold.

When finished, click Create Vector Database.
Provisioning can take several minutes depending on the cluster size and number of nodes.
Add a Trusted Source Using Automation
You can add trusted sources using the DigitalOcean CLI (doctl) or the API.
Add a Trusted Source via CLI
To add a trusted source using doctl, use doctl databases firewalls append with the database cluster ID and the trusted source type and value.
For list, remove, and other firewall commands, see doctl databases firewalls.
Add a Trusted Source via API
To add a trusted source using the API, send a PUT request to the database firewall endpoint with the cluster ID and the trusted source type and value.
Make Bulk Updates to Trusted Sources Using Automation
Bulk updates replace the cluster’s full trusted sources list. Use them when you need to add, remove, or replace multiple trusted sources in one operation.
Make Bulk Updates to Trusted Sources via CLI
To make bulk updates using doctl, use doctl databases firewalls replace with the full list of trusted sources you want the cluster to keep.
Make Bulk Updates to Trusted Sources via API
To make bulk updates using the API, send a PUT request to the database firewall endpoint with the full list of trusted sources you want the cluster to keep.
Add a Trusted Source Using the Control Panel
In the Control Panel, you can make bulk changes to trusted sources, but each source must be entered manually. To update many rules at once or replace the entire list in a single operation, use the API or CLI to make bulk updates to trusted sources.
To add trusted sources to restrict database access, go to the Databases page and select the cluster you want to add trusted sources to. Click the Network Access tab.
The Network Access page lists any trusted sources already added. An icon next to each trusted source indicates its resource type (for example, Droplet, App Platform app, tag, or Kubernetes cluster).

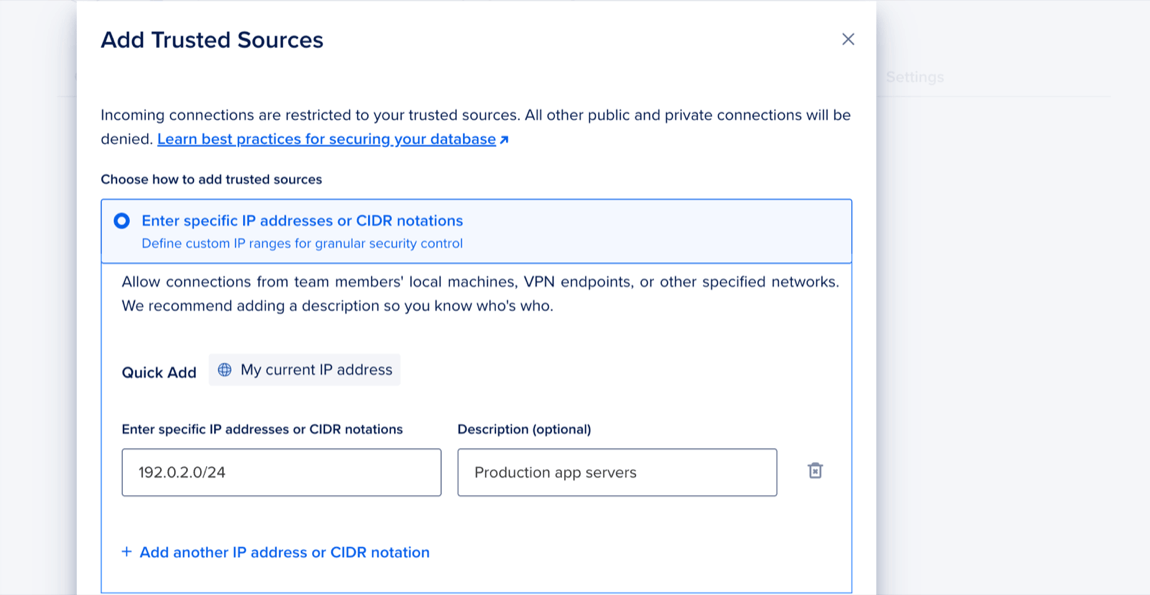
Click Add Trusted Sources. In the Add Trusted Sources window, choose one of the following options:
- Enter specific IP addresses or CIDR notations: Enter specific IP addresses or a CIDR range. Or click My current IP address to use the Quick Add option, which adds your machine’s current IP address.
- Quick select Droplets, Kubernetes clusters, Apps, and tags: Use the search to find a resource, or open the dropdown and select a resource from the list. The dropdown groups resources by type, such as Droplets, Applications, tags, and Kubernetes clusters.
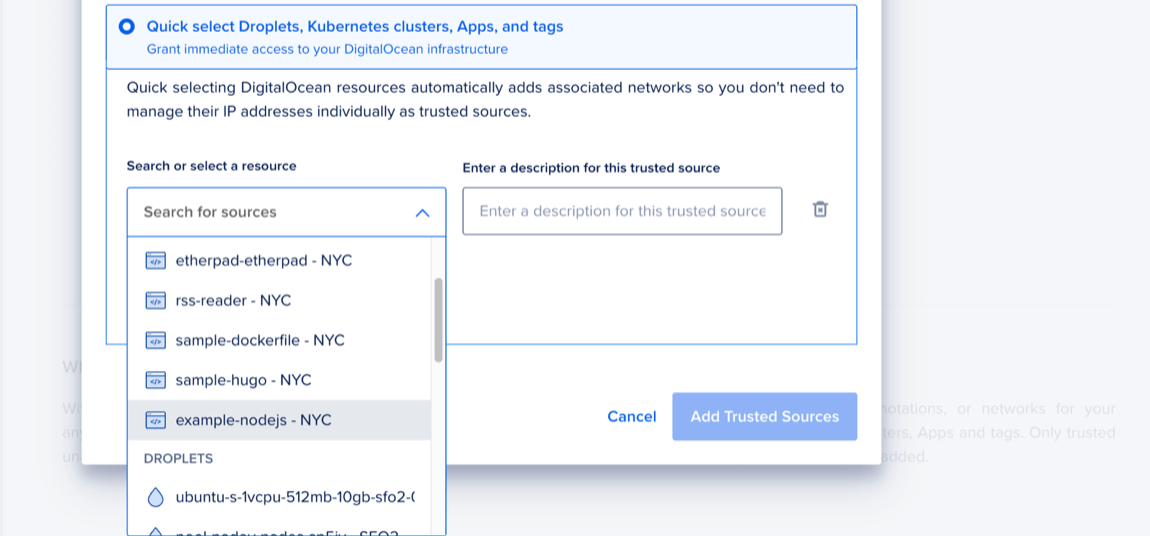
When finished, click Add Trusted Sources.
You currently cannot add IPv6 rules to a database cluster’s trusted sources.
Copy and Store Connection Details
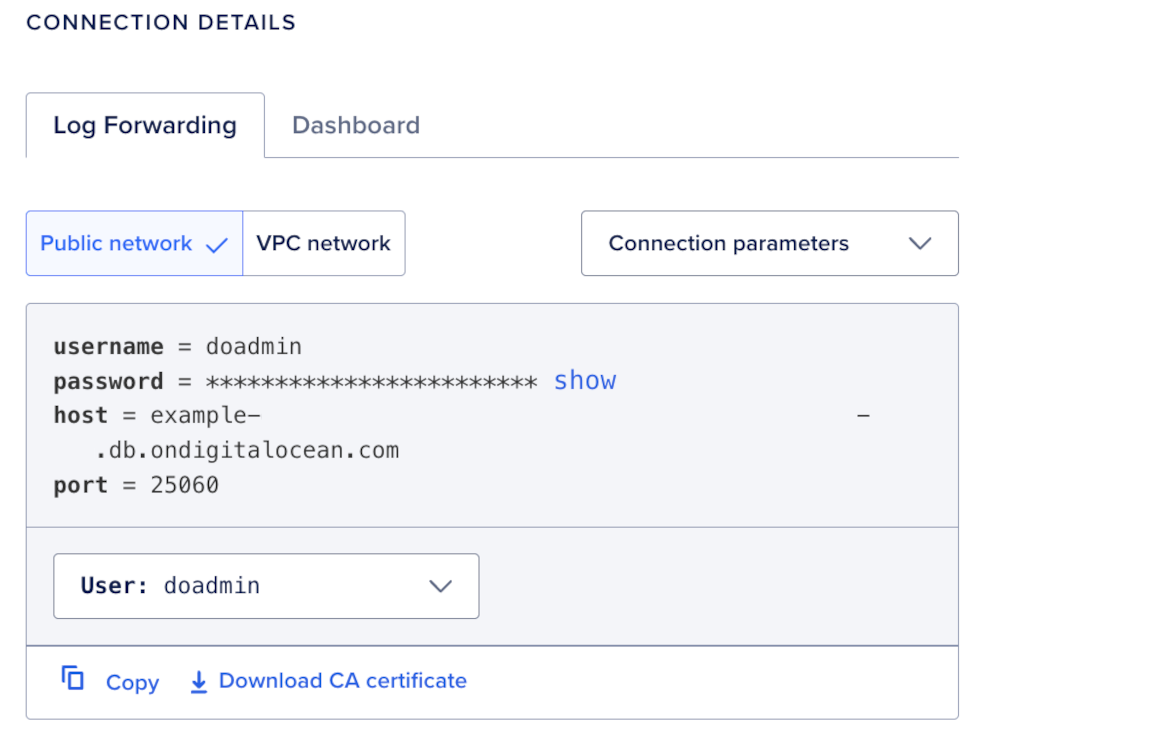
To copy and store your OpenSearch vector database cluster’s connection details for later use, go to the Control Panel, in the left menu, click DATA SERVICES, click Vector Databases, and then select the cluster you want to view connection details for.
Then, in the Overview tab, in the CONNECTION DETAILS section, copy the connection parameters for Public network, username, password, host, and port, then store them securely for later use.
Set Environment Variables for a Trusted Source
To set environment variables for a trusted source, open a terminal session using the trusted source you set up:
export OPENSEARCH_HOST="<your-cluster-host>"
export OPENSEARCH_PORT="<your-cluster-port>"
export OPENSEARCH_USER="<your-cluster-username>"
export OPENSEARCH_PASSWORD="<your-cluster-password>"
export OS="https://$OPENSEARCH_USER:$OPENSEARCH_PASSWORD@$OPENSEARCH_HOST:$OPENSEARCH_PORT"Replace <your-cluster-host>, <your-cluster-port>, <your-cluster-username>, and <your-cluster-password> with the values you saved from the cluster’s connection details.
If you added your current IP address as a trusted source, open the terminal from the same computer and network using that IP address.
If you added a DigitalOcean resource, such as a Droplet, as a trusted source, open a terminal session from that resource.
Lastly, verify the connection:
curl -sS "$OS/" | jq '.version.number'If successful, the command returns the OpenSearch version number.
After you store your connection details securely and set your environment variables, you can start indexing and running queries: